
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 파이썬
- 프로그래머스SQL
- sql
- orderby
- sorted
- 머신러닝
- Machine Learning
- DATE_FORMAT
- SQL공부
- groupby
- 코세라머신러닝강의
- map
- 안드류응
- POP
- coursera
- PYTHON
- mysql
- 코세라
- Andrew NG
- 코세라강의
- Algorithm
- programmers
- sql오답노트
- 인프런sql강의
- 코세라머신러닝
- 프로그래머스
- 머신러닝강의
- 알고리즘
- 경제공부
- WHERE
Archives
- Today
- Total
미래를 예측하는 데이터분석가
[Coursera] 머신러닝 Andrew Ng 강의 2주차 정리노트 - 2 본문
Machine Learning by professor Andrew Ng in Coursera
Day 5 - Computing Parameters Analytically
Normal Equation

정규방정식을 이용할 때 파라미터값을 구해주는 식은 위와 같다.
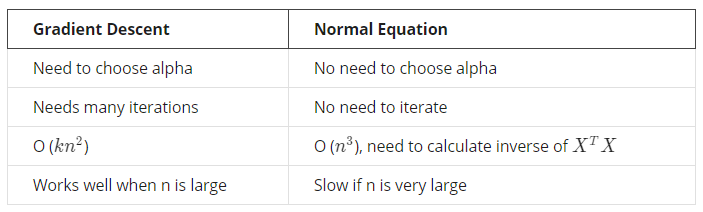
우선 정규방정식을 이용하면 스케일링을 해주지 않아도 된다는 점이 있고 위와 같이 특징들이 존재한다.
그레디언트의 경우 learning_rate를 설정해야하고 반복을 계속해서 진행하지만 정규방정식의 경우 그럴 필요가 없다.
그리고 속도면에서 feature수가 급격히 늘어날 수록 정규방정식의 속도가 느리기 때문에 그레디언트로 구하는 것이 낫다. 이런 점들을 잘 고려해 알고리즘을 설정하는 것이 중요하다고 생각한다.
Normal Equation Noninvertibility
정규방정식을 이용해 파라미터값을 구하기위해서는 X와 X의 역행렬을 곱해야하는데 X의 역행렬이 존재하지 않을 때는 어떻게 계산할 수 있느냐에 대한 질문을 바탕으로 설명해주셨다.
우선 feature들 중에서 서로 종속되어있는 경우와 너무 많은 feature들 (m<=n) 즉, data값보다 변수가 많은 경우에 일어난다.
그로인한 해결책이라면 feature중 필요없는 것들을 제거하거나 정규화를 시켜주는 것이 있다.
'강의노트 > Coursera' 카테고리의 다른 글
| [Coursera] 머신러닝 Andrew Ng 강의 3주차 정리노트 - 1 (0) | 2021.02.13 |
|---|---|
| 코세라 머신러닝 Octave 설치 및 과제 제출 (0) | 2021.02.12 |
| [Coursera] 머신러닝 Andrew Ng 강의 2주차 정리노트 - 1 (0) | 2021.02.05 |
| [Coursera] 머신러닝 Andrew Ng 강의 1주차 정리노트 - 3 (0) | 2021.02.03 |
| [Coursera] 머신러닝 Andrew Ng 강의 1주차 정리노트 - 2 (0) | 2021.02.02 |
'강의노트/Coursera' Related Articles
more



