
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- orderby
- Andrew NG
- DATE_FORMAT
- 인프런sql강의
- PYTHON
- 알고리즘
- sorted
- 파이썬
- 코세라머신러닝
- 머신러닝강의
- coursera
- 머신러닝
- sql오답노트
- groupby
- map
- mysql
- sql
- 코세라머신러닝강의
- Algorithm
- 안드류응
- 경제공부
- Machine Learning
- 코세라강의
- programmers
- SQL공부
- 프로그래머스
- 프로그래머스SQL
- POP
- WHERE
- 코세라
- Today
- Total
미래를 예측하는 데이터분석가
[Coursera] 머신러닝 Andrew Ng 강의 2주차 정리노트 - 1 본문
Machine Learning by professor Andrew Ng in Coursera
Day 4 - Linear Regression with Multiple Variables
Multivariate Linear Regression 즉, 다변량 회귀에서 Gradient Descent알고리즘이 어떻게 계산되는지를 배웠다.
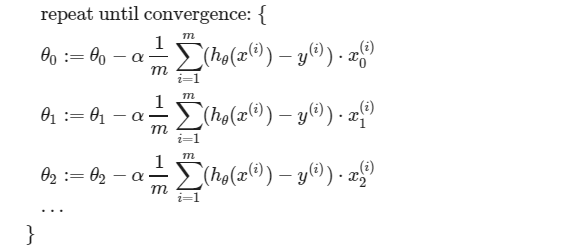
우선 위의 식을 보면 회귀의 절편값과 기울기들이 θ0, θ1, θ2로나타난다.
회귀식은 H(x) = θ0 + θ1x1+ θ2x2+...+θnxn이다.
여기서 위의 식들을 유추하는 과정은 day-2에 설명하셨고 Cost Function을 각 θi로 미분하여 기울기를 구해 각 θi에서
빼주면서 Cost Function이 가장 작아지는 최적의 파라미터값을 찾는 방법이었다.
그 식들을 간단히 요약하자면 다음과 같다.
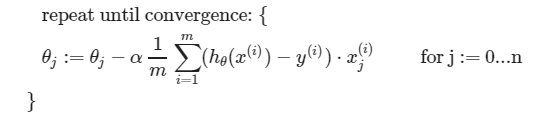
Gradient Descent in Practice I - Feature Scaling
Mean Normalization 이 왜 Gradient Descent 과정에서 쓰일까?

그 해답은 위와 같이 변수들의 단위크기가 너무 차이가 나면 Contour 그래프가 길게 나타나 Gradient Descent의 수행속도가 느려져 수렴이 느려지게 됩니다. 하지만 스케일링을 적용시켜 두 변수사이의 값의 차이를 비슷하게 만들어면 Contour 그래프가 원형에 가까워 훨씬 수렴속도가 개선됨을 볼 수 있습니다.
그리고 대표적으로 설명해주신 스케일링 기법은 Mean Normalization입니다.
Gradient Descent in Practice II - Learning Rate
Gradient Descent Algorith이 잘 작동하기 위해서 매 구간에서 Cost Function값이 작아져야 합니다.

반복수가 증가할수록 Cost Function의 값이 작아짐을 볼 수 있고 어느정도 작아지고 더 이상 1/1000이상으로 감소되지 ㅏ않으면 알고리즘을 중단하는 것이 좋다는 설명이다.

여기서 learning rate, α가 너무 작아져도 수렴이 느리므로 좋지않고 너무 커도 수렴하지 않고 값이 튕겨나가므로 좋지 않아 그 사이의 적적한 값을 찾아주는 것이 좋다.
Features and Polynomial Regression
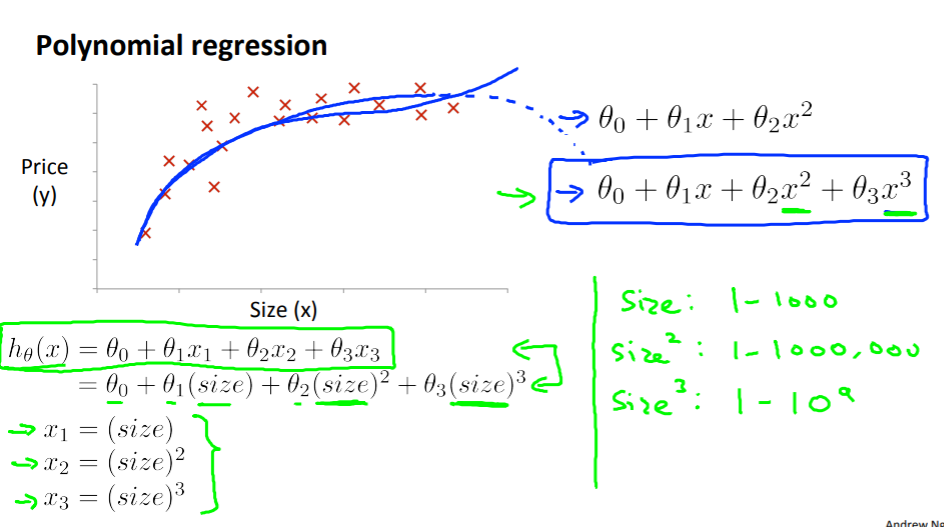
다항회귀일 때 곡선이 나타나며 변수의 단위 차이가 천차만별로 차이가 날 수 있다.
그래서 feature scaling을 해주면 좋을 경우가 많다는 것을 하나의 예시로 볼 수 있었다.
'강의노트 > Coursera' 카테고리의 다른 글
| 코세라 머신러닝 Octave 설치 및 과제 제출 (0) | 2021.02.12 |
|---|---|
| [Coursera] 머신러닝 Andrew Ng 강의 2주차 정리노트 - 2 (0) | 2021.02.08 |
| [Coursera] 머신러닝 Andrew Ng 강의 1주차 정리노트 - 3 (0) | 2021.02.03 |
| [Coursera] 머신러닝 Andrew Ng 강의 1주차 정리노트 - 2 (0) | 2021.02.02 |
| [Coursera] 머신러닝 Andrew Ng 강의 1주차 정리노트 (0) | 2021.02.01 |



